해당 포스트는 아직 한글화가 진행되지 않은 Projects on AWS : Create and Manage a Nonrelational Database with Amazon DynamoDB 자습서를 진행하면서 자습서의 내용을 한글로 옮기고, 자습서에는 나와있지 않지만 추가적으로 공부한 내용을 덧붙인 포스트이다.
추가적으로 공부를 하면서 참고한 링크는 포스트 하단에 링크해 두었다.
2. Inserting and retrieving data
이번 단계에서는 간단한 예제들을 통해 DynamoDB에 데이터를 넣어 보기도 하고, 검색해 보기도 할 것이다.
CreateTableAPI를 이용하여 DynamoDB에 table을 생성해 볼 것이고,BatchWriteItemAPI를 이용하여 DB에 데이터를insert해 볼 것이다.- 마지막으로
GetItemAPI를 이용하여 테이블에 있는 각각의 아이템들을 검색해 볼 것이다.
이 예제들을 직접 해 보기 전에, online bookstore application 예제의 data model에 대하여 생각해 볼 것이다.
다음에 이어지는 모듈들에서는 Query API를 이용하여 한번에 여러 아이템들을 검색하는 방법, secondary indexes (보조 인덱스)를 이용하여 추가적인 쿼리 패턴을 사용하는 방법을 배울 것이다. 또한 테이블에 이미 존재하는 아이템을 어떻게 update 하는지도 배울 것이다.
Terminology
아래에 적혀 있는 DynamoDB의 concept 들은 이번 모듈에서 꼭 알아 두어야 할 것들이다.
- Table
DynamoDB data records의 collection을 의미한다. - Item
DynamoDB table에 있는 하나의 data record를 의미한다. RDB(관계형 DB)에서의 row 1개와 동일한 개념이다. - Atribute
하나의 아이템에 있는 하나의element (요소)를 의미한다. RDB에서의 column 한 개와 동일한 개념이다.attribute의 타입은string,integer,boolean과 같은 심플한 타입과list와maps와 같은 복잡한 타입 모두 가능하다. - 하지만, RDB에서는 모든
attribute들이 테이블을 생성할 때 미리 정의되어 있어야 하는 것과 달리 DynamoDB에서는primary key를 제외한 다른 attribute들은 테이블을 생성할 시점에 정의되어 있을 필요가 없다. - primary key
primary key는 DynamoDB 테이블에 있는 하나의 아이템의 unique한 식별자이다. primary key의 이름과 타입은 테이블 생성 시에 정의되어야 하며, 테이블에 아이템을 생성할 때는 미리 정의된 타입의 primary key가 반드시 생성할 아이템에 포함되어 있어야 한다.예를 들어,UserID하나만을 식별자로 사용하는 단일 PK를 생성할 수도 있고,UserID와Creation_Date를 결합한 복합 PK를 식별자로 이용할 수도 있다. - 단일 PK는 하나의 attribute만을 담고 있고, 복합 PK는 두개의 attribute들(
partition key,sort key)로 구성된다.
Data model
application을 설계할 때, application logic에 맞는 data model을 디자인하는데 시간을 투자해야 한다. data model 디자인에서는 application에서 필요로 하는 data access를 고려해야 하는데, 여기에는 data에 대한 reading과 wrting이 모두 포함된다.
DynamoDB는 비관계형 데이터베이스이다. 비관계형 데이터베이스에서는 테이블을 생성하기 전에 스키마를 미리 완벽히 정의할 필요가 없다. 단지 테이블의 record들을 unique하게 식별할 primary key만 선언하면 될 뿐이다. 이러한 특징은 application에 필요한 데이터가 바뀔 때 마다 스키마를 쉽게 수정할 수 있도록 하여 data model을 디자인하는 cost를 줄여준다.
Introduction의 Application background 섹션에서 언급했듯이, 우리의 application은 책의 제목과 저자를 통해 각각의 book을 검색할 수 있어야 한다. title과 author의 결합이 book의 unique한 식별자이기 때문에 우리는 이 attribute들을 테이블의 PK로 사용할 수 있다.
우리의 application은 책의 정보를 저장할 때 history, biography와 같은 책의 category도 저장해야 하며, hardcover, papaerback, audiobook과 같은 책의 formats도 저장해야 한다.
이러한 점들을 고려하면 다음과 같은 스키마를 테이블에 사용할 수 있다.
- Title (a string) : 책의 제목
- Author (a string) : 책의 저자
- Category (a string) : 책의 카테고리(ex. History, Biography, Sci-Fi ...)
- Formats (a map) : 책의 형태(ex. hardcover, paperback, audiobook ...). 인벤토리 시스템에 존재하는 현재 판매하고 있는 책의 형태의 item number와 매핑됨.
다음의 몇 가지 단계에서 복합 PK(Autohr and Title)를 이용하여 테이블을 생성해보고, 생성된 테이블에 몇 가지 아이템을 insert 해 보고 테이블에 있는 각각의 아이템들을 read 해 보도록 하자.
STEP 1. Create a DynamoDB table
이전 단계에서 명령어를 통해 여러 파일을 다운받았는데, 다운받은 파일들 중 create_table.py 파일을 이용하여 DynamoDB에 테이블을 생성해 볼 것이다. create_table.py 파일은 CreateTable API를 사용하여 Books 테이블을 생성하는 스크립트이다.
AWS Cloud9의 탐색기에서 해당 파일을 클릭하면 스크립트 내용을 볼 수 있다. 해당 스크립트를 좀 뜯어보도록 하자.
create_table.py 뜯어보기
boto 3
import boto3
# boto3 is the AWS SDK library for Python.
# We can use the low-level client to make API calls to DynamoDB.
client = boto3.client('dynamodb', region_name='ap-northeast-2')먼저, Boto3에는 두 가지 수준의 API가 있는데, Client API와 Resources API가 존재한다. Client API는 기본 HTTP API 작업에 일대일 매핑을 제공하고, 리소스 API는 명시적인 네트워크 호출은 숨기지만 대신 속성에 액세스하고 작업을 수행할 수 있도록 리소스 객체 및 리소스 모음을 제공한다.
여기서 우리는 boto3.client를 이용하여 Client API를 이용할 것이다. DynamoDB에 대한 API가 필요하기 때문에 첫 번째 파라미터로 dynamodb를 주었고, 두 번째 파라미터는 해당 dynamodb의 리전을 뜻하는데 디폴트는 us-east-1으로 되어 있다.
만약, 아까 Cloud9을 생성하면서 같이 만든(즉, Cloud9이 걸려 있는) EC2의 리전이 us-east-1이 아니라면 EC2의 리전과 맞게 바꿔 주는 것이 좋을 듯 하다 보통 자신이 있는 리전에서 하는 작업만 프리티어에 반영되기도 하고, 내가 서울에 있는데 굳이 us-east-1을 사용하면 로딩 시간이 길어질 수가 있는 등(물리적인 것은 us에 있으니까 데이터가 미국에서부터 서울까지 전송되는 꼴..)의 애로사항이 있다. 따라서, 나는 region_name을 ap-northeast-2로 수정하였다.
현재 예제에서 사용되는 모든 .py 파일의 region_name을 동일한 것(ap-northeast-2)으로 바꾸어야 한다
자신의 EC2가 어디에 생성되었는지는 서비스 > EC2 > 실행 중인 인스턴스에서 해당 EC2를 클릭하고, 세부 정보에서 가용 영역 부분을 확인하면 된다.

create_table
try:
resp = client.create_table(
TableName="Books",
# Declare your Primary Key in the KeySchema argument
KeySchema=[
{
"AttributeName": "Author",
"KeyType": "HASH"
},
{
"AttributeName": "Title",
"KeyType": "RANGE"
}
],
# Any attributes used in KeySchema or Indexes must be declared in AttributeDefinitions
AttributeDefinitions=[
{
"AttributeName": "Author",
"AttributeType": "S"
},
{
"AttributeName": "Title",
"AttributeType": "S"
}
],다음 부분에서는 client.create_table과 같이 CreateTable API를 이용하여 테이블 이름이 Books인 테이블을 생성하려고 하는 모습을 볼 수 있다.
KeySchema
아까 위에서 언급했듯이, 테이블을 생성할 때 모든 attribute들에 대한 스키마가 정해질 필요는 없지만 PK에 대한 것은 반드시 정의되어있어야 한다고 했다. 해당 스크립트에서 PK를 정의하는 부분이 KeySchema 부분이다.
KeySchema부분을 살펴보면, Author와 Title attribute를 통해 복합 PK를 구성함을 알 수 있다. 여기서 Author 에는 HASH 키 타입이, Title 에는 RANGE 키 타입이 붙는데, 둘의 차이는 무엇일까?
이에 대한 내용은 DynamoDB의 Hash 타입 키와 Sort 타입 키에 적어두었다.
Hash key와 Range key에 대한 설명 위 링크를 참조하도록 하고, 다시 KeySchema 부분으로 돌아가 코드를 좀 살펴보면 복합 PK (partition key(hash key), sort key(range key))로 구성되며 Author 가 hash key 타입이고 Title 이 Range key 타입인 것을 알 수 있다.
KeySchema 부분은 Atribute들 중에서 어떤 것을 key로 사용하겠다는 것을 선언한 것으로, Author 와 Title attribute를 key로 사용하려면 Author 와 Title 의 attribution에 대한 정의가 필요하다.
AttributeDefinitions
이는 그 다음 부분인 AttributeDefinitions에서 정의되어 있다. 스크립트를 살펴보면 Author 와 Title attribute가 정의되어 있는 것을 알 수 있고 두 attribute 모두 S(string) 타입으로 선언되어 있는 것을 알 수 있다.
ProvisionedThroughput
ProvisionedThroughput={
"ReadCapacityUnits": 1,
"WriteCapacityUnits": 1
}
)
print("Table created successfully!")
except Exception as e:
print("Error creating table:")
print(e)
hash key와 sort key 설명 중 partitioning에서의 이슈 때문에 provisioning throughput 이슈가 생긴다고 했는데, 이 부분에 대한 설정을 하는 것이 여기이다.
ReadCapacityUnits는 DynamoDB가 ThrottlingException을 반환하기 전에 초당 사용되는 Strongly Consistent Read 의 최대 수 이다. WriteCapacityUnits는 DynamoDB가 ThrottlingException을 반환하기 전에 초당 사용되는 최대 쓰기 수 이다.
create_table.py 실행하기
여기까지 create_table.py 스크립트를 뜯어보았고, 해당 스크립트를 실행시켜보자.
AWS Cloud9 터미널에 다음의 명령어를 입력하여 해당 스크립트를 실행시켜서 Books 테이블을 만들어 보자.
python create_table.py정상적으로 테이블이 생성되면 다음과 같은 로그가 뜰 것이다.

테이블이 생성된 후 aws console을 살펴보면 다음과 같이 생성된 Books 테이블을 확인할 수 있다.

STEP 2. Load items into the table
이제 테이블에 아이템을 넣어보자. insert_items.py는 BatchWriter API를 통해 테이블에 아이템을 넣는 스크립트이다.
insert_items.py 뜯어보기
스크립트는 다음과 같이 짜여져 있다.
속성에 액세스하고 작업을 수행할 수 있도록 리소스 객체 및 리소스 모음을 제공하는 Resource API를 사용한다.
import boto3
# boto3 is the AWS SDK library for Python.
# The "resources" interface allow for a higher-level abstraction than the low-level client interface.
# More details here: http://boto3.readthedocs.io/en/latest/guide/resources.html
dynamodb = boto3.resource('dynamodb', region_name='ap-northeast-2')
table = dynamodb.Table('Books')
# The BatchWriteItem API allows us to write multiple items to a table in one request.
with table.batch_writer() as batch:
batch.put_item(Item={"Author": "John Grisham", "Title": "The Rainmaker",
"Category": "Suspense", "Formats": { "Hardcover": "J4SUKVGU", "Paperback": "D7YF4FCX" } })
batch.put_item(Item={"Author": "John Grisham", "Title": "The Firm",
"Category": "Suspense", "Formats": { "Hardcover": "Q7QWE3U2",
"Paperback": "ZVZAYY4F", "Audiobook": "DJ9KS9NM" } })
batch.put_item(Item={"Author": "James Patterson", "Title": "Along Came a Spider",
"Category": "Suspense", "Formats": { "Hardcover": "C9NR6RJ7",
"Paperback": "37JVGDZG", "Audiobook": "6348WX3U" } })
batch.put_item(Item={"Author": "Dr. Seuss", "Title": "Green Eggs and Ham",
"Category": "Children", "Formats": { "Hardcover": "GVJZQ7JK",
"Paperback": "A4TFUR98", "Audiobook": "XWMGHW96" } })
batch.put_item(Item={"Author": "William Shakespeare", "Title": "Hamlet",
"Category": "Drama", "Formats": { "Hardcover": "GVJZQ7JK",
"Paperback": "A4TFUR98", "Audiobook": "XWMGHW96" } })스크립트를 살펴보면, dynamodb.Table('Books').batch_writer().put_item(Item={})을 이용하여 테이블에 아이템을 하나씩 넣는 모습을 볼 수 있다.
이때 주목해야 할 것은 각 아이템마다 PK인 Author와 Title가 정의되어 있음을 알 수 있다. 또한 Category 와 Formats 는 각 책의 추가 정보를 알려주기 위해 붙었음을 알 수 있다. Category 는 simple type인 string으로, Formats 는 complex type인 map 으로 구성됨을 알 수 있다.
insert_items.py 실행하기
이제 해당 스크립트를 실행하여 item을 테이블에 삽입해 보자.
python insert_items.py별다른 에러가 없으면 데이터가 잘 들어간 것이고, 이는 aws console의 DynamoDB > 테이블 을 통해서도 확인할 수 있다.
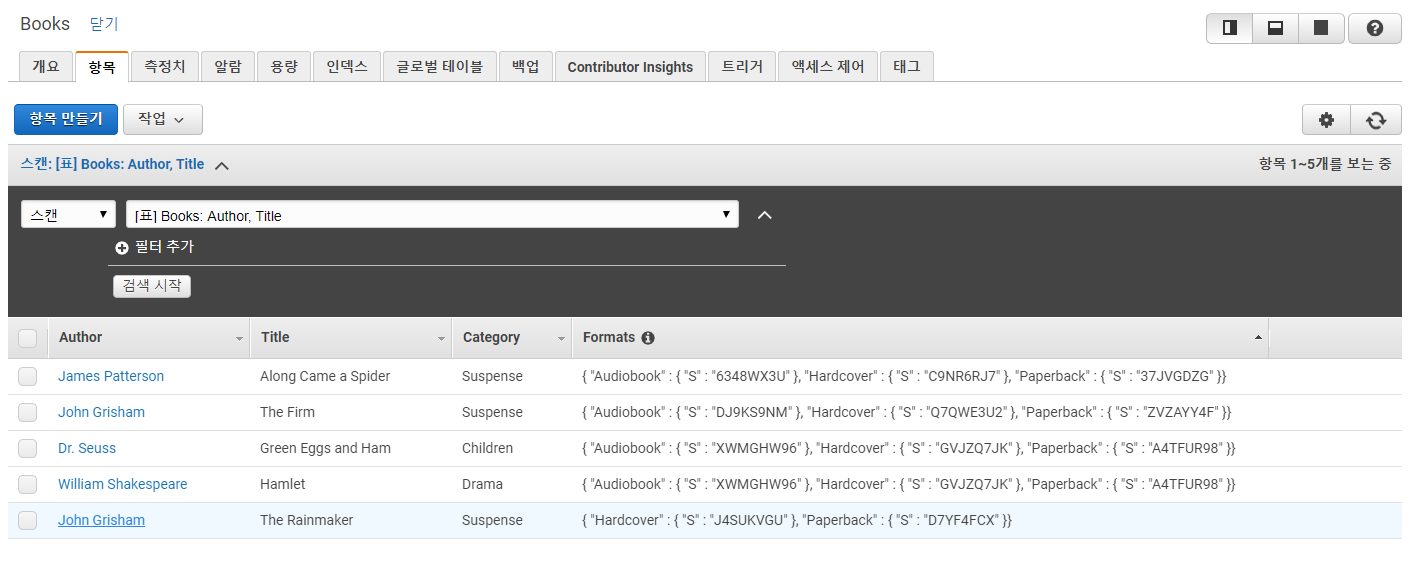
여기서 강조하고 넘어가야 할 것은 우리가 Boto 3 client library를 이용하여 HTTP API 방식으로 데이터를 insert 하였다는 것이다. RDBMS를 이용하여 data의 access와 manipulation을 하기 위해서는 DB와의 connections을 유지하고 있어야 하지만, DynamoDB는 그럴 필요 없이 필요할 때에만 HTTP API를 이용하여 요청을 보내면 된다.
STEP 3. Retrive items from the table
이제 테이블에서 아이템을 검색해 보자. get_item.py 스크립트는 GetItem API를 이용하여 테이블에서 아이템을 검색하는 스크립트이다.
get_item.py 뜯어보기
get_item.py는 다음과 같이 구성되어 있다.
import boto3
# boto3 is the AWS SDK library for Python.
# The "resources" interface allow for a higher-level abstraction than the low-level client interface.
# More details here: http://boto3.readthedocs.io/en/latest/guide/resources.html
dynamodb = boto3.resource('dynamodb', region_name='ap-northeast-2')
table = dynamodb.Table('Books')
# When making a GetItem call, we specify the Primary Key attributes defined on our table for the desired item.
resp = table.get_item(Key={"Author": "John Grisham", "Title": "The Rainmaker"})
print(resp['Item'])boto3.resource.Table('Books').get_item(Key = {})로 테이블의 이름과 PK에 대한 정보를 넘긴다. 아이템을 검색할 때는 PK를 통해 검색을 해야 하므로, PK에 대한 정보가 꼭 필요하다.
get_item.py 실행하기
python get_item.py스크립트를 실행하면 다음과 같이 정보를 잘 가져왔음을 알 수 있다.

여기까지가 2. Inserting and retrieving data 모듈의 내용이다. 다음 모듈에서는 하나의 API 호출로 여러 아이템을 검색하는 방법에 대해서 알아보고, secondary index(보조 인덱스)를 활용하여 multiple data에 access하는 방법에 대해 알아본다.
'잡다한 시리즈 > AWS' 카테고리의 다른 글
| AWS DynamoDB를 이용하여 비관계형 DB 구축하기 - (1) Application background (0) | 2021.03.19 |
|---|---|
| DynamoDB의 Hash key와 Sort key (0) | 2021.03.19 |