Kafka... Message Queue... Active MQ.... MSA 구조의 시스템을 다루다보면 꼭 등장하는 친구이다. 그 중 현업에서 쓰고 있는 Kafka에 대해 정리해보기로 한다.
Kafka는 따지고보면 설명할 내용이 굉장히 많기 때문에, 이 포스트에서는 가장 상위의 개념만을 다루기로 하고 세부적인 매커니즘은 다른 포스트에서 다루기로 한다.
Kafka란 무엇인가?
카프카는 MQ(Message Queue)의 한 종류이다.
단, 다음의 특징으로 인해 실시간으로 많은 데이터를 처리해야 하거나, 장애가 없어야 하는 시스템에서 많이 채택된다.
1. 높은 처리량 & 손 쉬운 스케일링
2. HA
3. 단순 메세지 전달 기능을 넘어, 데이터 저장소의 역할을 함
그렇다면 근본적으로 왜 카프카, 아니 왜 MQ를 쓰는 것인가?
그 이유는 시스템의 결합도를 낮춰서 성능을 높이고, 장애에 효율적으로 대응하기 위해서다.
Monolithic 구조에서 MSA(MicroServices Architecture) 구조로 넘어가면서, 프로세스간 통신이 성능에 중요한 영향을 미치게 되었다. 예를 들어, 작업 A가 끝난 뒤 작업 B를 실행해야 온전한 시스템 처리가 끝나는 구조라고 해 보자. MSA구조를 채택할 경우 A, B 프로세스 두개가 따로 뜰 것이며 A 프로세스에서 B 프로세스로 동기/비동기 방법을 통해 데이터를 넘겨야 한다.
이때, 동기적 처리를 선택할 경우 B 프로세스의 failure가 A에도 영향을 미친다. 왜냐하면 A에서 정상 처리된 데이터를 B로 넘긴 후, B에서의 정상 처리 응답을 기다리고 있을 것이다. 기다리는 동안 다른 데이터의 처리는 불가능하기 때문에 전체적인 시스템 성능이 떨어진다.
비동기적 처리를 선택할 경우, A는 일단 작업을 잘 마쳤으니 냅다 B에 데이터를 던지고 다른 일을 하러 간다. 물론 B의 성능은 전체적인 시스템의 성능에 영향을 미치긴 하지만, 동기적 처리에 비해 A라도 일을 할 수 있다.
비동기적 처리를 하는 방법에는 MQ, Publish-Subscribe, Webhook 등등 많은 방법이 있다. 그 중에서 시스템의 환경과 요구사항에 맞는 방법을 채택하면 되는데, 나의 경우에는 Kafka가 선택된 것이다.
Kafka의 기본 구성 요소, Producer-Partition-Consumer
카프카에 대해 한번이라도 들어봤다면 Producer, Partition, Consumer 이 세 가지는 무조건 같이 들어봤을 것이다.
개념적으로 쉽게 말하면
1. 전달해야하는 메세지를 Producer를 통해 Partition(Queue)에 적재하고,
2. 해당 메세지를 처리해야하는 쪽에서 Consumer를 통해 메세지를 가져간다.
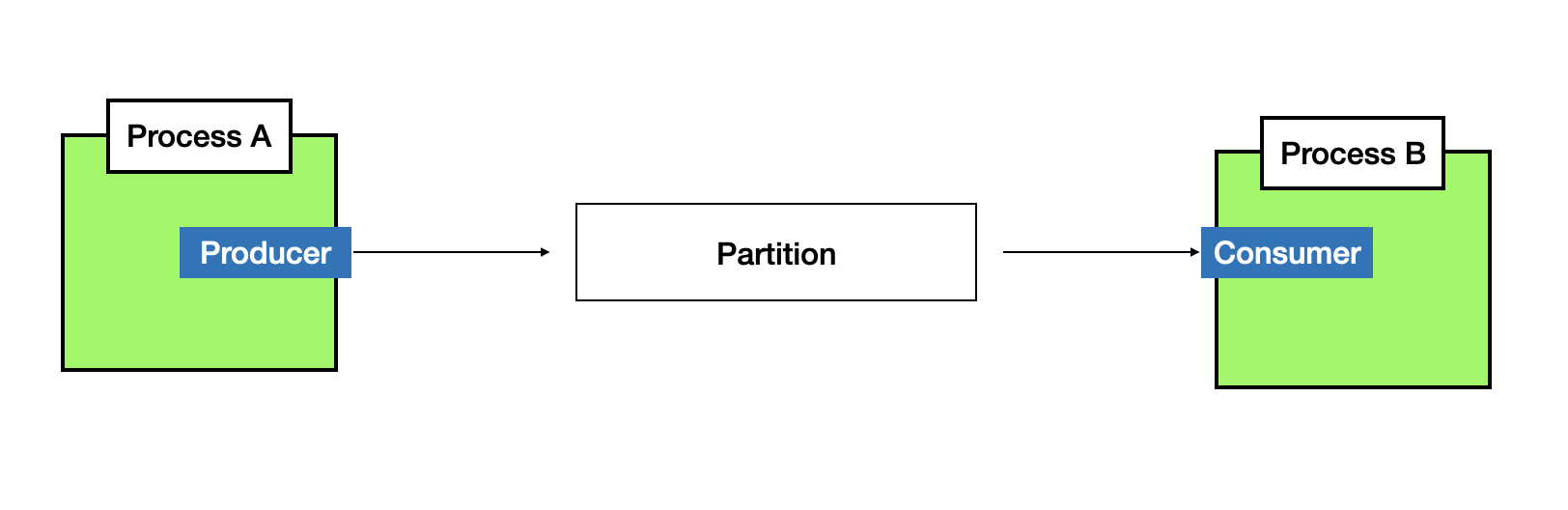
Partition은 Queue와 똑같다. 똑같은게 아니라 그냥 Queue의 형태로 구현되어 있는 것이다.
그렇다면 위의 상황에서 A, B와 전혀 다른 일을 하는 프로세스 C가 프로세스 D에게 데이터를 전달하려고 하면 위의 구조도는 어떻게 되어야 할까? Partition 1을 만들어야할까? 아니다. 여기서 Partition의 상위 개념인 Topic이 나온다.

Topic. 직역하면,, '주제' 쯤 될까? 주제에 상관없이 하나의 queue에 메세지를 때려넣으면, 대체 이 메세지를 가져가서 처리해야 하는게 어떤 프로세스인지 알기가 어려울 것이다. 따라서, 카프카는 Topic을 기준으로 Queue를 생성하여 메세지가 섞이지 않게 해 준다.
자 그럼 다음 단계로 가기 위해 Process C와 D는 다시 기억에서 지워버리자.
맨 처음에 Kafka를 쓰는 이유중에 하나로 높은 처리량을 언급했었다. 그렇다면 위 구조에서 처리량을 높이기 위해서는 어떻게 해야 할까?
Consumer쪽의 처리량을 먼저 생각해보자. 처리량을 높이는 대표적인 방법에는 scale-out이 있다. 현재의 구조에서 Consumer를 여러개 둔다고 해서, 처리량이 극도로 높아질까? 높아지긴 하겠지만 엄청난 성능 향상을 기대할 수는 없다. 왜냐하면 메세지를 전달받을 수 있는 통로인 Queue(Partition)이 하나이기 때문이다.
scale-out을 하는 이유는 병렬처리를 위함이다. Consumer를 여러개 두고, 병렬처리를 하기 위해서는 구조가 어떻게 되어야 할까? 정답은 바로 하나의 Topic에 여러개의 Partition을 두면 된다.
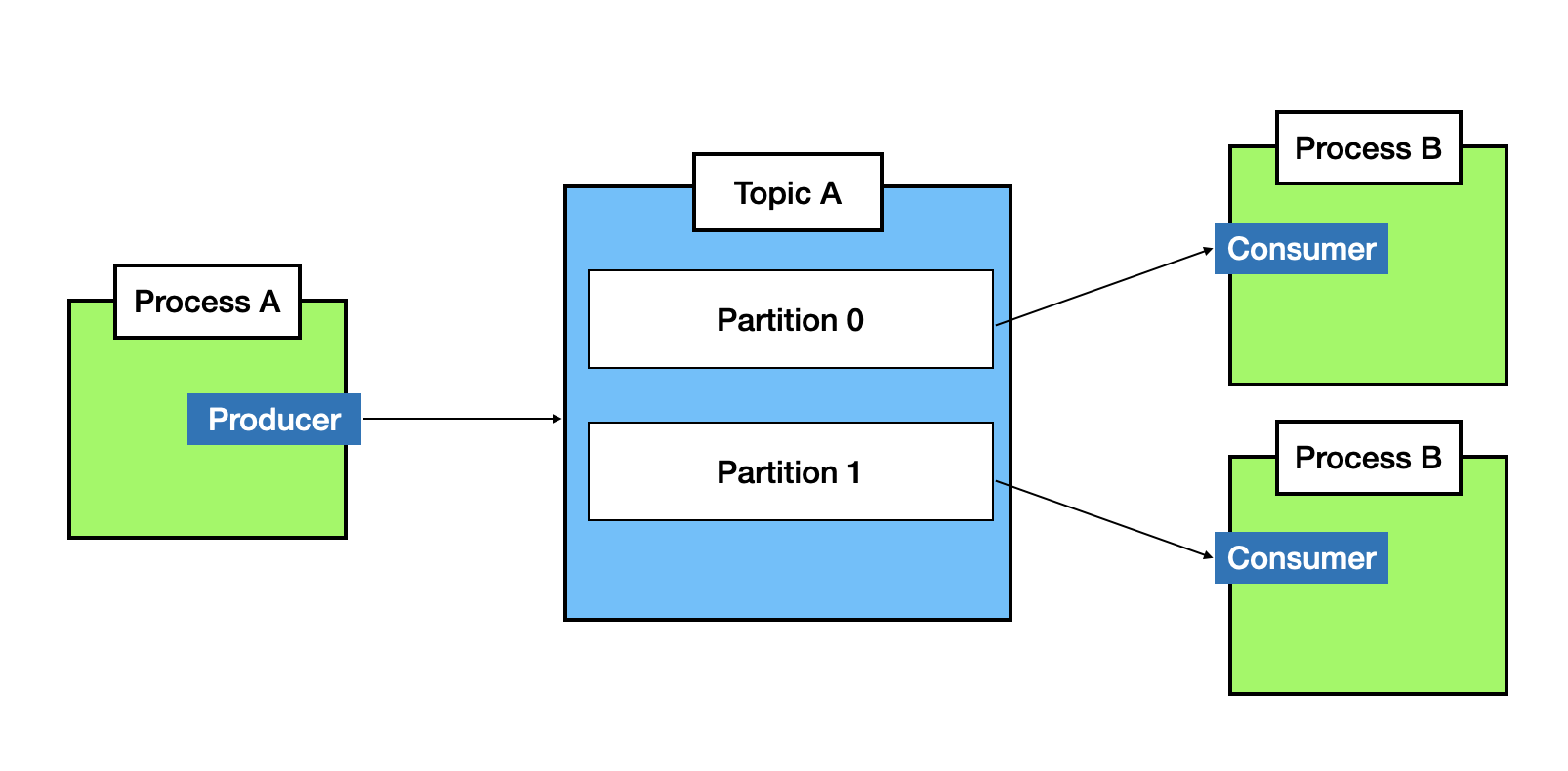
Producer가 메세지를 두 개의 Partition에 적절히 분배해서 넣어줄 수 있다면, Process B는 병렬처리가 가능하게 된다. Partition의 수를 늘리고, Consumer의 수를 늘릴수록 그 처리량은 비례해서 높아질 것이다.
이번 포스트에서는 Kafka의 필요성과 Kafka의 기본 구성 요소인 Producer, Partition, Consumer에 대해 알아보았다.
개인적으로 어떤 것을 공부할때 '얘가 왜 필요한데?', '왜 써야 하는데?'를 이해하지 못하면 암기를 하지 못하는 편이라, 내가 이해한 순서대로 서술해 보았다. 처음에 딱 Kafka에 대해서 공부할때 토픽이란 이런거고, 토픽 안에는 파티션이 여러개가 있어요! 이렇게 외우니까 전혀 이해가 안됐기 때문이다..
아무튼 카프카에 대해 차차 더 세부적인 내용을 다뤄보겠다. 오늘은 끝!
'잡다한 시리즈 > 개발' 카테고리의 다른 글
| TDD를 배우고 경험해보며 쌓아가는 이야기 (0) | 2023.03.20 |
|---|---|
| [Java] 테스트 코드 생성하고 돌리기 (0) | 2023.02.12 |
| [Git] core.autocrlf, IntelliJ Line Separators Warnings (0) | 2023.02.12 |
| Apple M1 macOS Gradle 설치하기 (0) | 2021.12.15 |
| Apple M1 macOS Oracle Java 17 또는 OpenJDK 설치하기 (10) | 2021.12.14 |